
Teaching AI to Play Tetris using Reinforcement Learning
Graduate Project
Project Goal
The goal of this project was to build a Tetris-playing AI agent that improved with experience and cleared over 10,000 lines on average before losing.
Challenges
Choosing the features to include in the cost function was the most critical design choice for this project. This decision was important because too few features can limit the performance of the agent while too many irrelevant features can cause the agent to learn based off features that are not helpful to the problem.
State representation is also a challenge for designing artificial players. On the standard Tetris game, the total number of states is 1060 which cannot be explored directly. Therefore, approximation and learning techniques must be implemented. The learning strategy must converge quickly and optimize the cost function based on a combination of exploitation and exploration in order to achieve the best performance.
My Solution
The reinforcement learning framework involved extracting relevant features from the environment, using them to set up a linear cost function, simulating the cost for all possible actions, using these costs to inform the decision-making process, and repeating until the agent loses the game. During training, the top eight performing agents of a generation (training iteration) make up an elite set and move on to the next generation. This elite set is then used to “reproduce” 32 “child” parameter sets. These steps repeat for 20 generations and the best-performing agent in the final generation is selected as the optimized parameter set.
Features were chosen based on aspects of the game that the player will want to either minimize or maximize. For instance, a successful player will likely try to maximize the number of cleared lines while avoiding features such as holes, row transitions, and column transitions. Additionally, a linear cost function was chosen due to its simple structure, which can reduce training time. The program only needs to learn coefficients associated with each feature as opposed to polynomials, combination functions, or other nonlinear functions.
Notable Features & Accomplishments
- Algorithms are implemented in an OpenAI Gym environment where 5 roll-outs are simulated for each parameter set and the average reward is evaluated.
- One agent learned through a genetic algorithm which kept elite sets of reward function parameters while producing other similar sets to use in the next generation.
- A second agent learned through the cross-entropy method which uses a sampling-based search for control environments then updates the distribution based on which samples scored the highest.
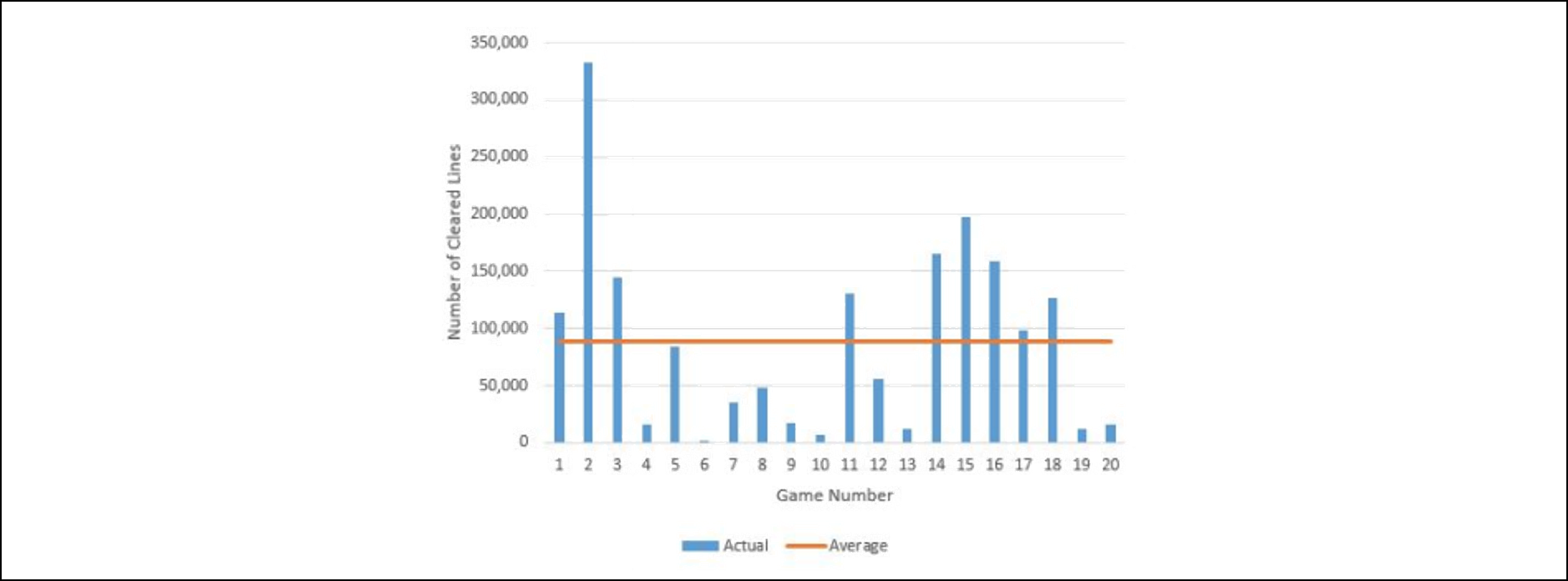
- The optimized AI agent cleared an average of 88,563 lines and the maximum cleared lines in a single game was 332,896. The Guinness Record for lines cleared by a human player is 4,988.
Skills Used
- Python
- Reinforcement Learning
- Algorithm Implementation
- Black Box Optimization
- Genetic / Evolutionary Algorithms
- Feature Selection
- Feature Engineering
- Monte Carlo Methods
- Cross-Entropy Method
- OpenAI Gym
- Simulation